





Technische Informatik
Die Technische Informatik in Heidelberg ist vernetzt mit vielen Forschungsbereichen der Universität, in denen Daten erfasst werden oder rechenintensive Aufgaben zu bewältigen sind. Für Problemstellungen im Bereich von Sensorik oder Datenkommunikation hat ZITI die Kompetenz, Mikrochips von Grund auf neu zu entwerfen und in Betrieb zu nehmen. Datenkommunikation verursacht oft einen Großteil des Energieverbrauchs, dies wird auf der Hardware-Ebene, durch hardwarenahe Programmierung und angepasste Systemarchitekturen behandelt. Neben der effizienten Programmierung moderner Prozessoren werden verschiedene Koprozessoren (FPGAs, GPUs, ML Prozessoren) am ZITI betrieben, um deren spezifische Stärken auszunutzen und Methoden und Arbeitsflüsse für höchst effiziente Datenverarbeitung zu erforschen.
Chip Entwurf

In der Gruppe für Schaltungstechnik werden mikroelektronische Chips entwickelt, getestet und angewandt. Diese Chips enthalten meist sehr sensitive, rauscharme Verstärker zur Signalerfassung und weitere Blöcke zur analogen Filterung, Digitalisierung oder digitalen Nachverarbeitung der Daten. Manche Chips enthalten direkt Strukturen zum Nachweis von Teilchen oder (einzelnen) Photonen. Die wesentlichen analogen Teile der Chips werden vollständig manuell entworfen und simuliert. Komplexe digitale Teile werden mit geeigneten Sprachen beschrieben und mit einer aufwändigen Software in mehreren Schritten in ein Layout übersetzt. Beide Teile werden dann vereint. Die Chips werden in modernen CMOS Technologien hergestellt und in der Arbeitsgruppe mit geeigneter Auslesehardware (meist FPGA Boards) in Betrieb genommen.
Beispielprojekte sind Chips zur Auslese von Teilchendetektoren (s. Bild), Detektorchips für Einzelphotonen zur Suche nach dunkler Materie oder für die Mikroskopie, Hybride Pixeldetektoren zum Nachweis von Synchrotron-Röntgenstrahlen beim Eu-XFEL oder an der ESRF oder Chips für State-of-the-Art PET Scanner.
Rechnersysteme
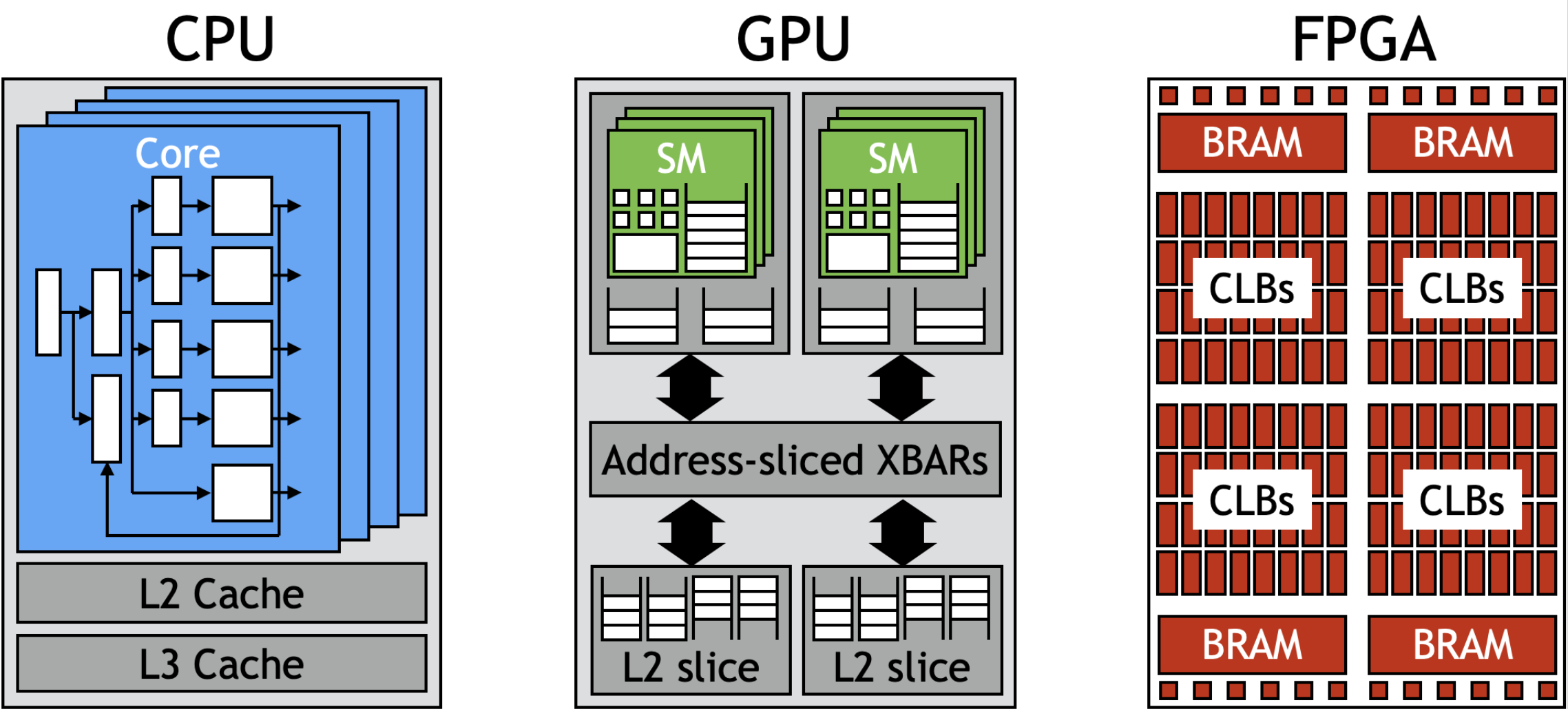
Die Forschung im Bereich der Rechensysteme befasst sich heute vor allem mit spezialisierten Formen des Rechnens in Kombination mit der nahtlosen Integration in bestehende Systeme. Spezialisierte Rechensysteme, z. B. auf der Grundlage von GPUs (wie sie für Gaming bekannt sind) oder FPGAs (Field Programmable Gate Arrays) oder ASICs (nicht die Schuhmarke, sondern anwendungsspezifische integrierte Schaltkreise
), werden durch abnehmende Erträge aus der Skalierung der CMOS-Technologie und harte Leistungsbeschränkungen motiviert. Bei einem festen Leistungsbudget definiert die Energieeffizienz die Leistung : . Eine nachhaltige Leistungsskalierung auf der Basis der CMOS-Technologie setzt also voraus, dass die Energieeffizienz von Rechen- und Speicheroperationen erheblich verbessert wird, was typischerweise durch die oben erwähnten spezialisierten Formen des Rechnens geschieht. Jede Spezialisierung steht jedoch im Gegensatz zur generischen Nutzung und wirft daher verschiedene Fragen in Bezug auf Programmierbarkeit und algorithmische Innovation auf.
Besondere Forschungsschwerpunkte sind:
- ressourceneffiziente ML wie Modellkompression für Edge-, mobile und eingebettete Systeme,
- Code-Analyse und -Generierung, z. B. auf der Grundlage von CLANG/LLVM und mit Blick auf (Multi-)GPU-Systeme,
- HW/SW-Codesign zur Erfüllung von Anwendungszielen durch eine umfassende Behandlung von Software- und Hardwarekomponenten
- spezialisierte Prozessorarchitekturen unter Berücksichtigung von Leistungs-, Energieeffizienz- und Programmierbarkeitsbeschränkungen
Die Gruppe befasst sich vor allem mit der Überbrückung der Kluft zwischen Anwendung und Hardware, einschließlich automatisierter Werkzeuge sowie abstrakter Modelle, die die (automatisierten) Überlegungen über verschiedene Optimierungen und Entscheidungen erleichtern.
Anwendungsspezifisches Rechnen
Unsere Forschung beschäftigt sich mit der signifikanten Verbesserung von Leistung und Genauigkeit im anwendungsspezifischen Rechnen durch eine globale Optimierung des gesamten Spektrums von numerischen Methoden, Algorithmenentwurf, Softwareimplementierung und Hardwarebeschleunigung.
Diese Ebenen haben in der Regel widersprüchliche Anforderungen und ihre Integration stellt viele Herausforderungen dar. So weisen numerisch überlegene Methoden wenig Parallelität auf, bandbreiteneffiziente Algorithmen verwickeln die Verarbeitung von Raum und Zeit in unüberschaubare Softwaremuster, Hochsprachenabstraktionen schaffen Barrieren für Datenlayout und Komposition und hohe Leistung auf heutiger Hardware stellt strenge Anforderungen an parallele Ausführung und Datenzugriff. Eine hohe Leistung und Genauigkeit für die gesamte Anwendung kann nur erreicht werden, wenn diese Anforderungen über alle Ebenen hinweg ausgeglichen werden.
Den folgenden Themen widmen wir besondere Aufmerksamkeit:
- Datendarstellung (gemischte Genauigkeiten, Kompression, Redundanz)
- Datenzugriff (Layout, räumliche und zeitliche Lokalität)
- Datenstruktur (unstrukturierte Gitter, Graphen, Adaptivität)
- Numerische Methoden (ILU, Krylov, GMG, AMG)
- Programmierabstraktionen (CUDA, Thrust, PSTL, C++2x, UPC++)
Forschungsgruppenleiter
Entwicklung von mikroelektronischen Schaltungen und Sensorsystemen zum Nachweis von Teilchen und Photonen

Zukünftige und neue Technologien (GPUs, FPGAs, ASICs, resistiver RAM) für Hochleistungsrechner, ressourcenbeschränktes Maschinelles Lernen und Datenanalyse

Parallele Algorithmen und Hardware (GPU, Many-Core-CPU, FPGA) in Bezug auf Datendarstellung, Datenzugriff, Datenstruktur, numerische Methoden und Programmierabstraktionen
